
Redis学习笔记
Redis数据结构
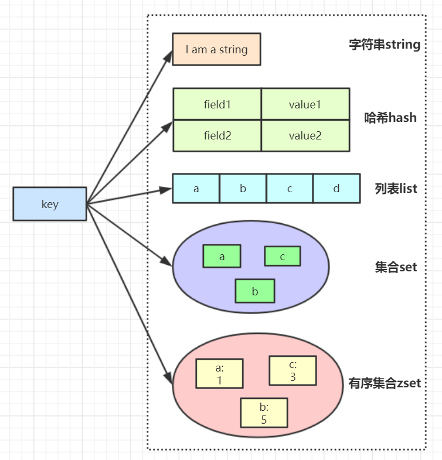
常用数据结构及命令
- 字符串常用操作
1 | SET key value //存入字符串键值对 |
- 原子加减
1 | INCR key //将key中储存的数字值加1 |
- 单值缓存
1 | SET key value |
- 对象缓存
1 | 1) SET user:1 value(json格式数据) |
- 分布式锁
1 | SETNX product:10001 true //返回1代表获取锁成功 |
- 计数器
1 | INCR article:readcount:{文章id} |
- 分布式系统全局序列号
1 | INCRBY orderId 1000 //redis批量生成序列号提升性能 |
Hash结构常用操作
1 | HSET key field value //存储一个哈希表key的键值 |
- 对象缓存
1 | HMSET user {userId}:name zhuge {userId}:balance 1888 |
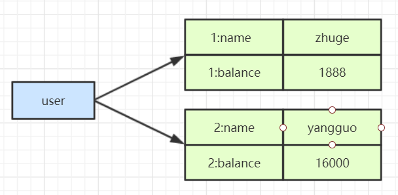
- 优点
- 同类数据归类整合储存,方便数据管理
- 相比string操作消耗内存与cpu更小
- 相比string储存更节省空间
- 缺点
- 过期功能不能使用在field上,只能用在key上
- 1)Redis集群架构下不适合大规模使用
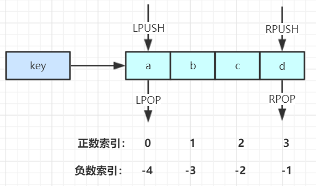
List常用操作
1 | LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边) |
Set常用操作
1 | SADD key member [member ...] //往集合key中存入元素,元素存在则忽略, |
- Set运算操作
1 | SINTER key [key ...] //交集运算 |
- 应用-微信抽奖小程序
1 | 1)点击参与抽奖加入集合 |
- 应用-微信微博点赞,收藏,标签
1 | 1) 点赞 |
- 集合操作
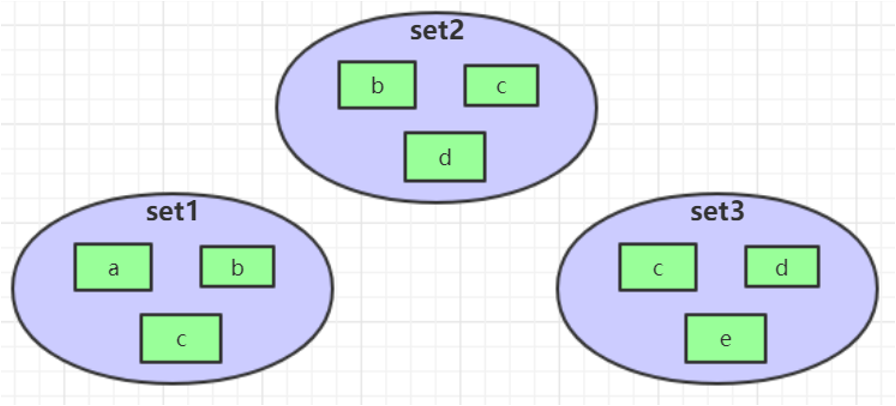
1 | SINTER set1 set2 set3 → { c } |
ZSet常用操作
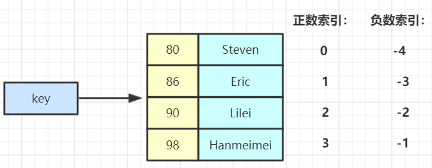
1 | ZADD key score member [[score member]…] //往有序集合key中加入带分值元素 |
- Zset集合操作
1 | ZUNIONSTORE destkey numkeys key [key ...] //并集计算 |
- 应用-Zset集合操作实现排行榜
1 | 1)点击新闻 |
Redis常讨论的问题
- Redis是单线程吗?
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外 提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
- Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性 能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如 keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
- Redis 单线程如何处理那么多的并发客户端连接?
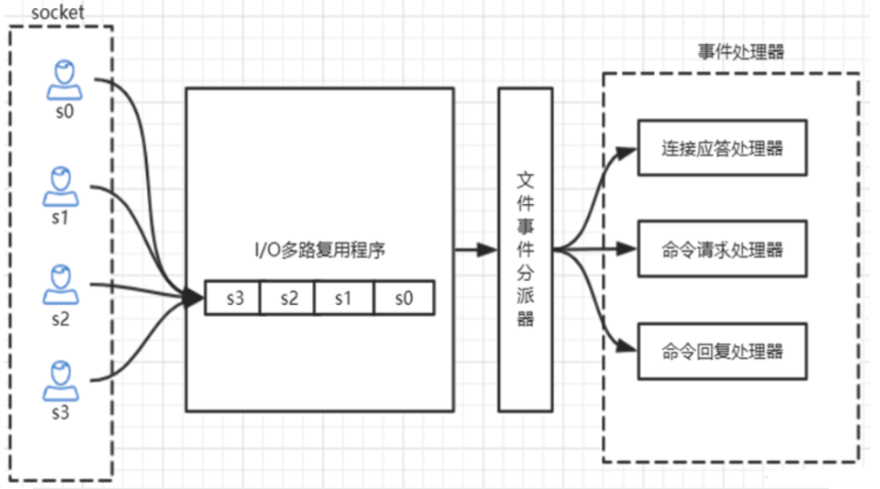
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到 文件事件分派器,事件分派器将事件分发给事件处理器。
1 | 查看redis支持的最大连接数,在redis.conf文件中可修改,# maxclients 10000 |
其他高级命令
Info:查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
- Server 服务器运行的环境参数
- Clients 客户端相关信息
- Memory 服务器运行内存统计数据
- Persistence 持久化信息
- Stats 通用统计数据
- Replication 主从复制相关信息
- CPU CPU 使用情况
- Cluster 集群信息
- KeySpace 键值对统计数量信息
Redis持久化
RDB快照(snapshot)
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。
你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次 数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次 数据集:
# save 60 1000 //关闭RDB只需要将所有的save保存策略注释掉即可
还可以手动执行命令生成RDB快照,进入redis客户端执行命令save或bgsave可以生成dump.rdb文件,每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
- bgsave的写时复制(COW)机制
Redis 借助操作系统提供的写时复制技术(Copy-On-Write, COW),在生成快照的同时,依然可以正常 处理写命令。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。 bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些 数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那 么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文 件,而在这个过程中,主线程仍然可以直接修改原来的数据。
- save与bgsave对比:
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函 数时会有短暂阻塞) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置自动生成rdb文件后台使用的是bgsave方式。
AOF(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方 式: AOF 持久化,将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间 fsync到磁盘)
比如执行命令“set zhuge 666”,aof文件里会记录如下数据
1 | *3 |
这是一种resp协议格式数据,星号后面的数字代表命令有多少个参数,$号后面的数字代表这个参数有几 个字符 注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的 时间戳
比如执行“set goudan 888 ex 1000”,对应aof文件里记录如下
1 | *3 |
你可以通过修改配置文件来打开 AOF 功能:
# appendonly yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
这样的话, 当 Redis 重新启动时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目 的。
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。有三个选项:
1 | appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。 |
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
- AOF重写
AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据生成aof文件 例如,执行了如下几条命令:
1 | incr readcount |
重写后AOF文件里变成
1 | *3 |
如下两个配置可以控制AOF自动重写频率
1 | auto‐aof‐rewrite‐min‐size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就 很快,重写的意义不大 |
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF, 注意,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多 影响
RDB 和 AOF ,我应该用哪一个?
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof 一般来说数据更全一点。
Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重 放,但是重放 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很 长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。 通过如下配置可以开启混合持久化(必须先开启aof):
# aof‐use‐rdb‐preamble yes
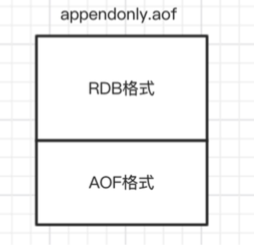
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将 重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一 起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改 名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下
- Redis数据备份策略:
- 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48 小时的备份
- 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
- 每次copy备份的时候,都把太旧的备份给删了
- 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
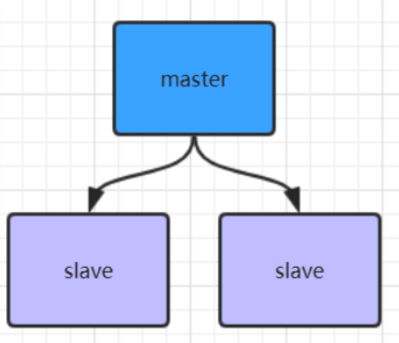
Redis主从架构
redis主从架构搭建,配置从节点步骤:
1 | 1、复制一份redis.conf文件 2 |
- Redis主从工作原理
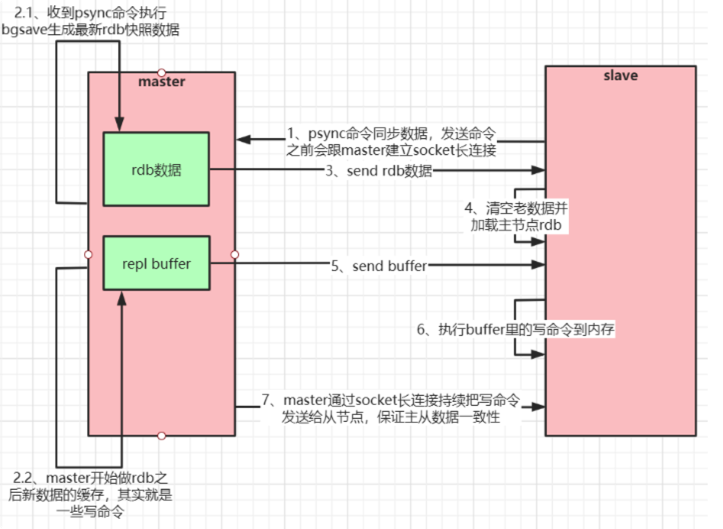
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。 master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完 毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后 再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。 当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多 个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送 给多个并发连接的slave。
- 主从复制(全量复制)流程图
数据部分复制
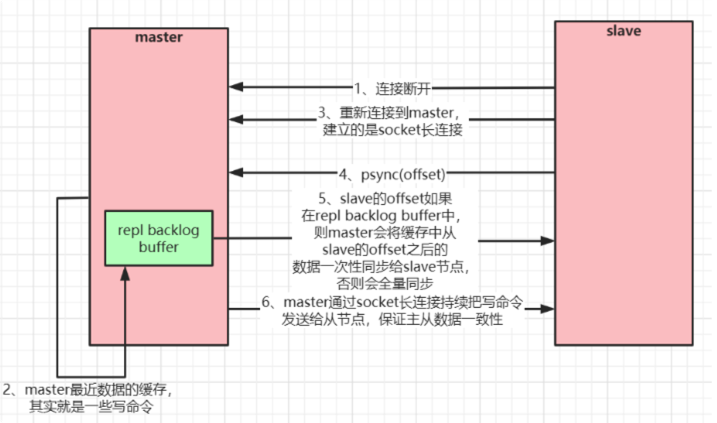
当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支 持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分 数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的 slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master 继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标 offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
- 主从复制(部分复制,断点续传)流程图
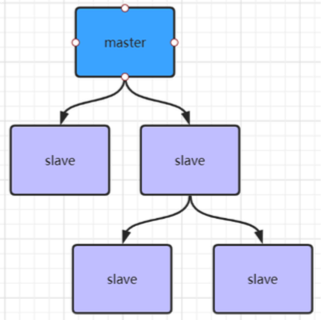
如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如 下架构,让部分从节点与从节点(与主节点同步)同步数据
Jedis连接代码示例
引入相关依赖:
1
2
3
4
5<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>访问代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public static void main(String[] args) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeot的构造函数
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "test-hfin.rdb.58dns.org", 50356, 3000, "xxxxxxxx");
Jedis jedis;
//从redis连接池里拿出一个连接执行命令
jedis = jedisPool.getResource();
System.out.println(jedis.set("single", "苟蛋"));
System.out.println(jedis.get("single"));
}
Redis哨兵高可用架构
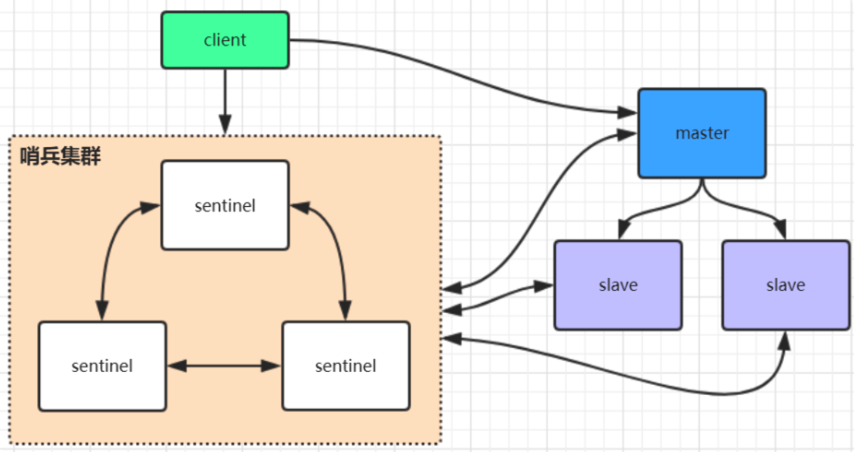
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。
哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过 sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis 主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
- redis哨兵架构搭建步骤:
1 | 1、复制一份sentinel.conf文件 |
sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的 最下面),我们查看下如下配置文件sentinel-26379.conf,如下所示
1 | sentinelknown‐replica mymaster 192.168.0.606380 #代表redis主节点的从节点信息 |
当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件 的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel文件里的集 群元数据信息会变成如下所示:
1 | sentinelknown‐replica mymaster 192.168.0.606379 #代表主节点的从节点信息 |
同时还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380
sentinel monitor mymaster 192.168.0.60 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点 加入集群
Spring Boot整合Redis连接
- StringRedisTemplate与RedisTemplate详解
spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在 RedisTemplate中提供了几个常用的接口方法的使用,分别是:
1 | privateValueOperations<K,V>valueOps; |
- RedisTemplate中定义了对5种数据结构操作
1 | redisTemplate.opsForValue();//操作字符串 |
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作。
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存 的。
RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。
- Redis客户端命令对应的RedisTemplate中的方法列表
| String类型结构 | |
|---|---|
| Redis | RedisTemplate rt |
| set key value | rt.opsForValue().set(“key”,”value”) |
| get key | rt.opsForValue().get(“key”) |
| del key | rt.delete(“key”) |
| strlen key | rt.opsForValue().size(“key”) |
| getset key value | rt.opsForValue().getAndSet(“key”,”value”) |
| getrange key start end | rt.opsForValue().get(“key”,start,end) |
| append key value | rt.opsForValue().append(“key”,”value”) |
| Hash结构 | |
| hmset key field1 value1 field2 value2… | rt.opsForHash().putAll(“key”,map) //map是一个集合对象 |
| hset key field value | rt.opsForHash().put(“key”,”field”,”value”) |
| hexists key field | rt.opsForHash().hasKey(“key”,”field”) |
| hgetall key | rt.opsForHash().entries(“key”) //返回Map对象 |
| hvals key | rt.opsForHash().values(“key”) //返回List对象 |
| hkeys key | rt.opsForHash().keys(“key”) //返回List对象 |
| hmget key field1 field2… | rt.opsForHash().multiGet(“key”,keyList) |
| hsetnx key field value | rt.opsForHash().putIfAbsent(“key”,”field”,”value” |
| hdel key field1 field2 | rt.opsForHash().delete(“key”,”field1”,”field2”) |
| hget key field | rt.opsForHash().get(“key”,”field”) |
| List结构 | |
| lpush list node1 node2 node3… | rt.opsForList().leftPush(“list”,”node”) |
| rt.opsForList().leftPushAll(“list”,list) //list是集合对象 | |
| rpush list node1 node2 node3… | rt.opsForList().rightPush(“list”,”node”) |
| rt.opsForList().rightPushAll(“list”,list) //list是集合对象 | |
| lindex key index | rt.opsForList().index(“list”, index) |
| llen key | rt.opsForList().size(“key”) |
| lpop key | rt.opsForList().leftPop(“key”) |
| rpop key | rt.opsForList().rightPop(“key”) |
| lpushx list node | rt.opsForList().leftPushIfPresent(“list”,”node”) |
| rpushx list node | rt.opsForList().rightPushIfPresent(“list”,”node”) |
| lrange list start end | rt.opsForList().range(“list”,start,end) |
| lrem list count value | rt.opsForList().remove(“list”,count,”value”) |
| lset key index value | rt.opsForList().set(“list”,index,”value”) |
| Set结构 | |
| sadd key member1 member2… | rt.boundSetOps(“key”).add(“member1”,”member2”,…) |
| rt.opsForSet().add(“key”, set) //set是一个集合对象 | |
| scard key | rt.opsForSet().size(“key”) |
| sidff key1 key2 | rt.opsForSet().difference(“key1”,”key2”) //返回一个集合对象 |
| sinter key1 key2 | rt.opsForSet().intersect(“key1”,”key2”)//同上 |
| sunion key1 key2 | rt.opsForSet().union(“key1”,”key2”)//同上 |
| sdiffstore des key1 key2 | rt.opsForSet().differenceAndStore(“key1”,”key2”,”des”) |
| sinter des key1 key2 | rt.opsForSet().intersectAndStore(“key1”,”key2”,”des”) |
| sunionstore des key1 key2 | rt.opsForSet().unionAndStore(“key1”,”key2”,”des”) |
| sismember key member | rt.opsForSet().isMember(“key”,”member”) |
| smembers key | rt.opsForSet().members(“key”) |
| spop key | rt.opsForSet().pop(“key”) |
| srandmember key count | rt.opsForSet().randomMember(“key”,count) |
| srem key member1 member2… | rt.opsForSet().remove(“key”,”member1”,”member2”,…) |
高可用集群模式
在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异 常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现 一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持 很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的 效率
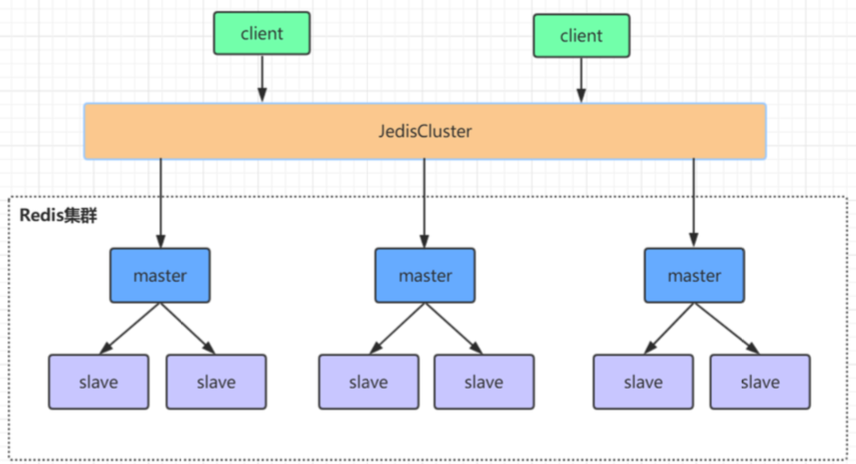
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需 要sentinel哨兵∙也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中 心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的 性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单
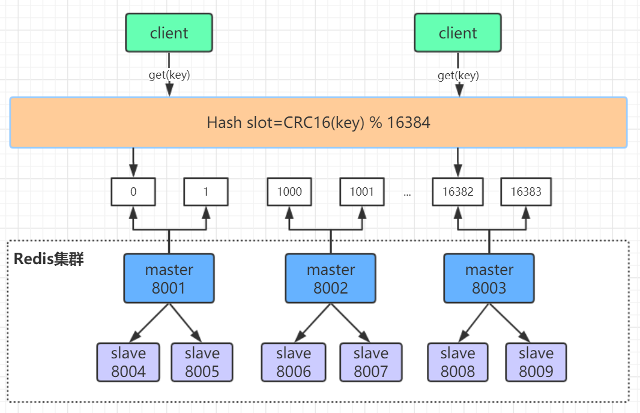
Redis集群原理分析
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每 个节点中。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这 样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不 一致的情况,还需要纠正机制来实现槽位信息的校验调整。
- 槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模 来得到具体槽位。
HASH_SLOT = CRC16(key) mod 16384
- 跳转重定位
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客 户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指 令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽 位映射表。

- Redis集群节点间的通信机制
redis cluster节点间采取gossip协议进行通信
维护集群的元数据(集群节点信息,主从角色,节点数量,各节点共享的数据等)有两种方式:集中式和gossip
- 集中式:
优点在于元数据的更新和读取,时效性非常好,一旦元数据出现变更立即就会更新到集中式的存储中,其他节 点读取的时候立即就可以立即感知到;不足在于所有的元数据的更新压力全部集中在一个地方,可能导致元数 据的存储压力。 很多中间件都会借助zookeeper集中式存储元数据。
- gossip:
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
- meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通 信;
- ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
- pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
- fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上 去更新,有一定的延时,降低了压力;缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
gossip通信的10000端口 每个节点都有一个专门用于节点间gossip通信的端口,就是自己提供服务的端口号+10000,比如7001,那么 用于节点间通信的就是17001端口。 每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几 点接收到ping消息之后返回pong消息。
- 网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见 的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频 繁切换 (数据的重新复制)。
Redis集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master 可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个 epoch只发送一次ack
- 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
- slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两 个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- slave广播Pong消息通知其他集群节点。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待 FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票 •延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方 式下,持有最新数据的slave将会首先发起选举(理论上)。
集群脑裂数据丢失问题
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复, 会将其中一个主节点变为从节点,这时会有大量数据丢失。
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制):
1 | min‐replicas‐to‐write 1 //写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,比如 集群总共三个节点可以配置1,加上leader就是2,超过了半数 |
注意:这个配置在一定程度上会影响集群的可用性,比如slave要是少于1个,这个集群就算leader正常也不能 提供服务了,需要具体场景权衡选择。
- 集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从 库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
- Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中 一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的 集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举 新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
- Redis集群对批量操作命令的支持
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如 果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计 算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去,示例如下:
1 | mset{user1}:1:name goudan{user1}:1:age18 |
假设name和age计算的hash slot值不一样,但是这条命令在集群下执行,redis只会用大括号里的 user1 做 hash slot计算,所以算出来的slot值肯定相同,最后都能落在同一slot。
哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进 行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的 leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一 个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移 操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。 哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨 兵节点就是哨兵leader了,可以正常选举新master。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点 类似。
redis 6.0新特性
- 多线程
- Client Side Cache
- Acls
多线程
redis 6.0 提供了多线程的支持,redis 6 以前的版本,严格来说也是多线程,只不过执行用户 命令的请求时单线程模型,还有一些线程用来执行后台任务, 比如 unlink 删除 大key,rdb持久 化等。
redis 6.0 提供了多线程的读写IO, 但是最终执行用户命令的线程依然是单线程的,这样,就没有 多线程数据的竞争关系,依然很高效。
- redis 6.0 线程执行模式:
1 | 可以通过如下参数配置多线程模型: 如: |
默认情况下,如上配置,有三个IO线程, 这三个IO线程只会执行 IO中的write 操作,也就是说, read 和 命令执行 都由main线程执行。最后多线程将数据写回到客户端。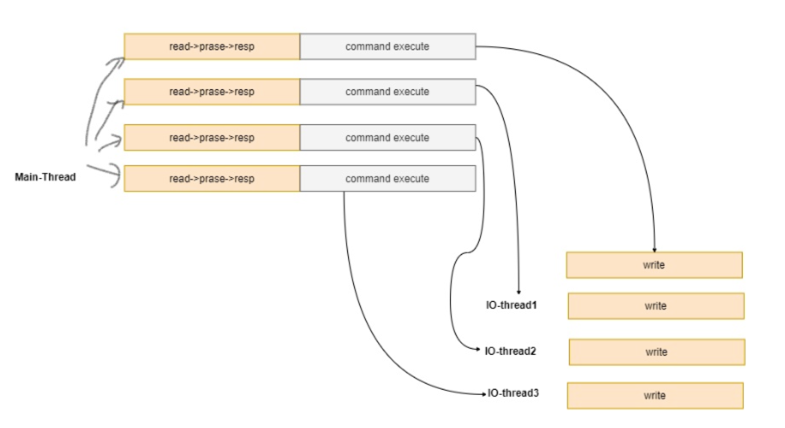
1 | 开启了如下参数: |
client side caching
客户端缓存:redis 6 提供了服务端追踪key的变化,客户端缓存数据的特性,这需要客户端实现
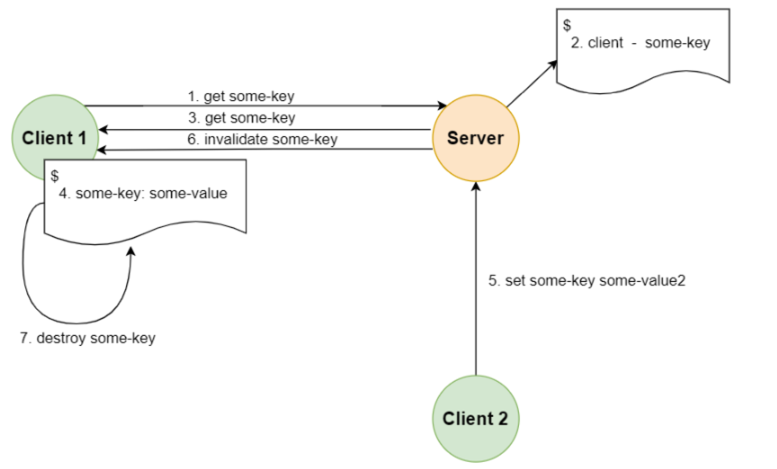
执行流程为, 当客户端访问某个key时,服务端将记录key 和 client ,客户端拿到数据后,进行 客户端缓存,这时,当key再次被访问时,key将被直接返回,避免了与redis 服务器的再次交 互,节省服务端资源,当数据被其他请求修改时,服务端将主动通知客户端失效的key,客户端 进行本地失效,下次请求时,重新获取最新数据。
1 | <!-- 目前只有lettuce对其进行了支持:--> |
ACL
ACL 是对于命令的访问和执行权限的控制,默认情况下,可以有执行任意的指令,兼容以前版 本
ACL设置有两种方式:
- 命令方式:ACL SETUSER + 具体的权限规则, 通过 ACL SAVE 进行持久化
- 对 ACL 配置文件进行编写,并且执行 ACL LOAD 进行加载
ACL存储有两种方式,但是两种方式不能同时配置,否则直接报错退出进程
- redis 配置文件: redis.conf
- ACL配置文件, 在redis.conf 中通过 aclfile /path 配置acl文件的路径
1 | 命令方式: |
用如上的命令创建的用户语义为:
- 处于 off 状态, 它是被禁用的,不能用auth进行认证
- 不能访问任何命令
- 不能访问任意的key
- 没有密码
如上用户alice 没有任何意义。
 微信
微信 支付宝
支付宝









